PaperQA2 is a useful reminder for scientific RAG: leave an evidence trail
A SciencesLoop technical note on PaperQA2, citation precision, and reviewable scientific RAG artifacts.
PaperQA2 is a useful reminder for scientific RAG: leave an evidence trail.
In materials and battery literature review, the expensive part is often not finding a paper. It is checking whether a conclusion is actually supported: were the experimental conditions comparable, was there a negative result, did the cited section really support the claim, and what would change the next experiment?
That is why Future-House/paper-qa, the open-source repository behind PaperQA2, caught my attention. The related paper is Language agents achieve superhuman synthesis of scientific knowledge.
My read: PaperQA2 is useful as a workflow signal. It breaks literature question answering into actions a researcher can inspect: search, evidence selection, reasoning over cited material, answer generation, and evaluation. Citations are the visible layer; the evidence path is the part I would want to audit.
SciencesLoop Signal Card
Workflow assessment
PaperQA2 evidence-trail pattern
The useful signal is the path from source search to cited claim to a reviewable next step. I have read the repo and paper; I have not run PaperQA2 locally yet.
Workflow stage Evidence -> evaluation -> reproducibility
- Signal
- Future House PaperQA2 repo + arXiv paper
- Run status
- Read repo and paper; not run locally yet
- Practical test
- Known-answer questions with near-miss papers and trace replay
-
Evidence qualityMed-high
-
ReproducibilityMedium
-
Workflow utilityHigh
-
Hype riskMedium
Why I paid attention: evidence trail is a reusable research artifact pattern, while the paper's strong performance framing still needs independent testing.
What the source actually says
From the public repository README, PaperQA2 is positioned as a package for high-accuracy retrieval-augmented generation over scientific literature. The README highlights a few concrete system capabilities:
- grounded answers with in-text citations
- metadata-aware document handling
- LLM-based reranking and contextual summarization
- agentic RAG, where the system can iteratively refine queries and answers
- local full-text search over a repository of documents
- configurable model and embedding backends through LiteLLM
The paper adds a stronger visual signal: PaperQA2 is presented as an agentic toolset with multiple operations around search, answering, contradiction detection, and evaluation. It also reports benchmark results across question answering, article summarization, and contradiction detection. Those reported results are source claims from the paper, not my independent benchmark.
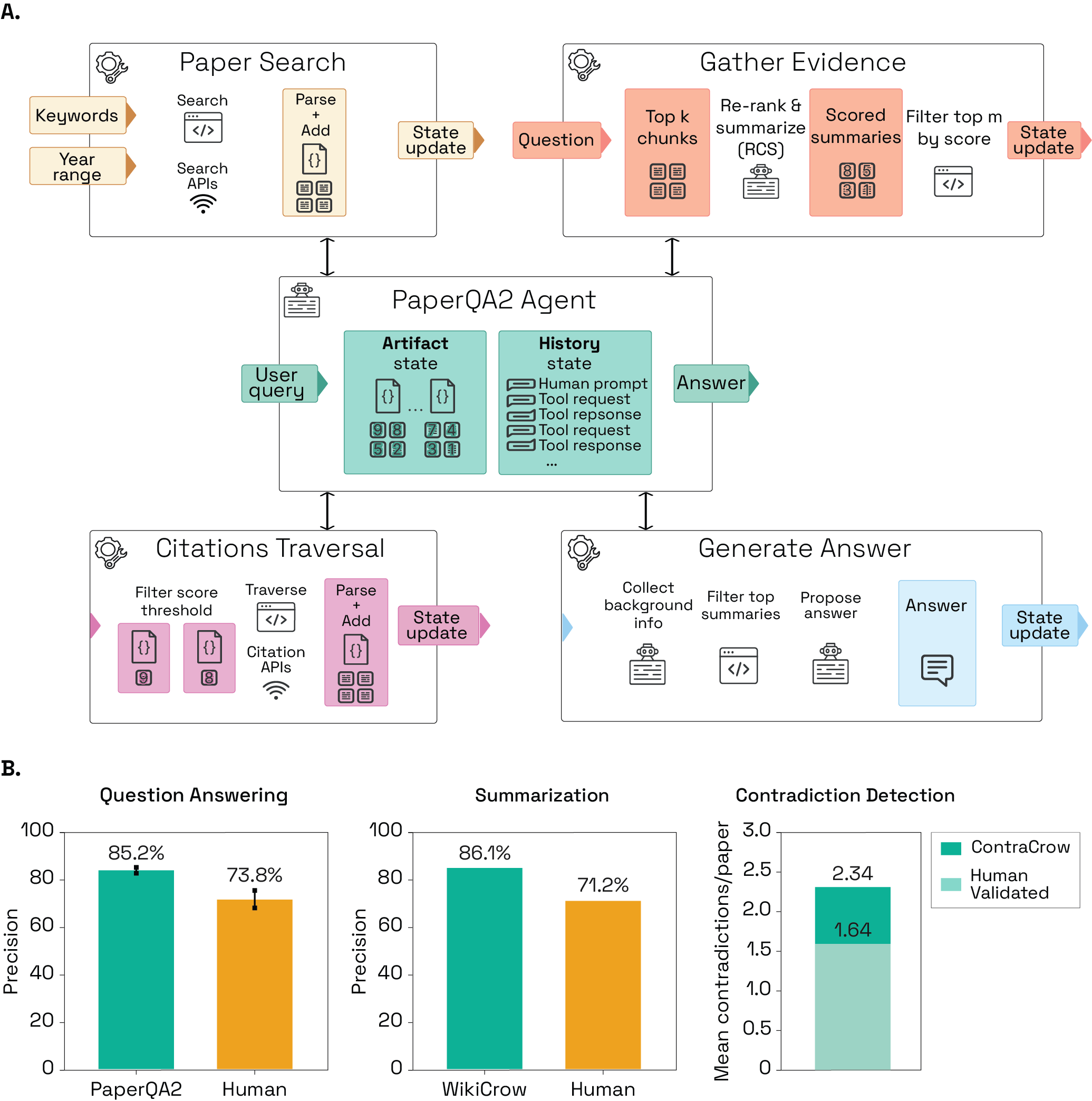
Figure 1 is the reason this signal is interesting for SciencesLoop. It puts search tools, answer generation, citation behavior, and evaluation in the same frame. That is closer to how scientific work actually happens: a question becomes a series of evidence operations before it becomes a decision.
The useful pattern
For a scientific agent, the answer is only one artifact. The path is the part another scientist needs in order to inspect it.

This is closer to a lab notebook than a chatbot. A useful lab notebook records more than “this electrolyte looks promising.” It records what was measured, under what conditions, what failed, and what the next reasonable test should be. A scientific RAG system should have the same spirit: the response should be inspectable after the fact.
The design move I want to keep is to treat every step as a work product:
- The query is a work product because it defines what the system actually looked for.
- The retrieved papers and sections are work products because they define the evidence base.
- The extracted claims are work products because they can be checked against the source.
- The answer is a work product because it summarizes a decision.
- The caveat is a work product because it controls overconfidence.
- The next step is a work product because it connects reading to action.
That is the part I want to carry into SciencesLoop. The useful output is something a scientist can audit, correct, and reuse.
A concrete scenario
Imagine a battery researcher asking:
Which classes of redox-active molecules have evidence for improved stability in nonaqueous flow batteries?
A weak assistant gives a confident paragraph and a few paper titles. That may be useful for orientation. It still leaves the researcher doing the trust work afterward.
A stronger scientific workflow would return something more structured.

The difference is small on the surface but large in practice. One output asks the researcher to trust the model. The other gives the researcher something to audit.
This is where a metaphor helps, but only if it has limits. I would avoid calling this “an AI scientist.” That phrase hides too much. A better mental model is:
a literature assistant that behaves like a lab notebook, a search analyst, and a careful reviewer.
The notebook records what happened. The search analyst finds and ranks evidence. The reviewer asks whether the evidence actually supports the claim. None of those roles replaces the scientist. Together they reduce the cost of inspection.
Beyond Better Search
Search retrieves documents. Scientific work needs a chain of responsibility across documents, claims, and actions.
In an AI-for-science setting, a RAG system may sit upstream of real decisions: which paper to read, which molecule to synthesize, which simulation to run, which dataset to trust, or which experimental protocol deserves time. That makes the retrieval layer part of the scientific workflow, not a convenience feature.
This is where PaperQA2 is a useful signal. Its public materials emphasize citation-grounded answers and agentic query refinement. Whether a given deployment is good depends on the corpus, models, settings, evaluation set, and human review process. My practical criterion is simple: retrieval and citation behavior need to be testable.
The PaperQA2 paper’s Figure 2 is useful because it pairs an example question and answer with performance and retrieval-stage analysis. I read that as a good communication pattern: show the user-facing answer together with the evaluation surface behind it.
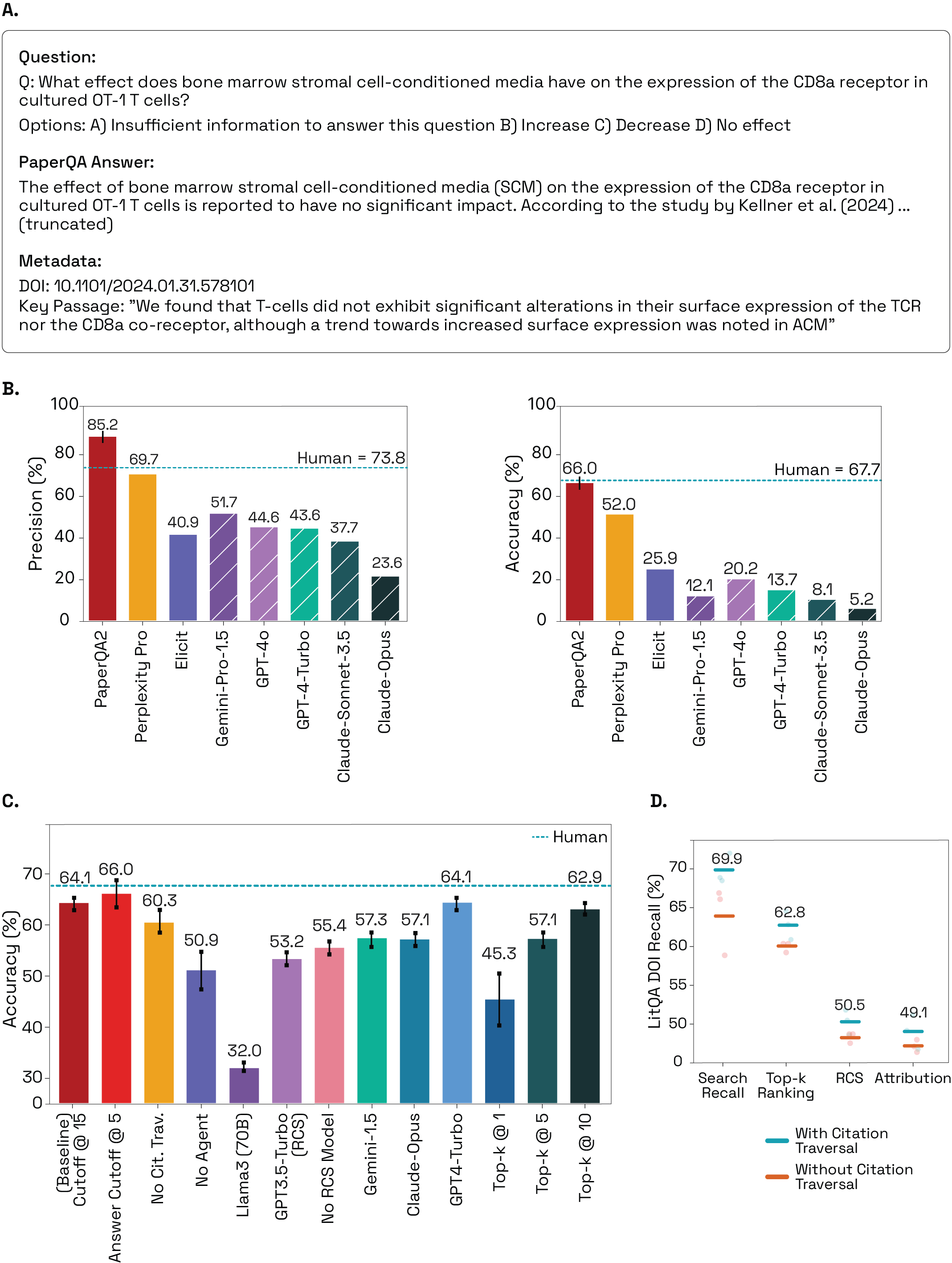
My conclusion from this figure is practical: if a scientific agent cannot show how it moved from search recall to selected context to attribution, it is hard to know whether the answer is reliable or merely fluent.
What I would test first
Before trusting any scientific RAG system, I would start with a small benchmark where the answer is already known.
For example:
- Pick 20 domain questions with known source papers.
- Include near-miss papers that use similar terminology but do not answer the question.
- Ask the system to answer with citations and uncertainty.
- Score citation precision, answer correctness, and whether the caveat is visible.
- Inspect failure cases manually.

The most interesting failures are usually not dramatic hallucinations. They are quieter:
- the system cites a relevant paper but the wrong section
- it merges two claims that were measured under different conditions
- it misses a negative result
- it overstates what a benchmark or paper actually showed
- it gives a reasonable answer without enough trace to audit
Those are the failures that matter in scientific work.
This is also why I do not want the article or the product to frame scientific agents as magic. The correct ambition is more grounded: make the reasoning path easier to inspect, make failure cases easier to find, and make the next human decision better informed.
The SciencesLoop angle
For SciencesLoop, this reinforces a simple design principle:
I want a scientific agent to deliver a research artifact that another person can inspect, correct, and reuse.
A scientific agent interface should probably show the answer together with the evidence trail, retrieval trace, source list, evaluation result, and next-step recommendation. It should be possible for a scientist to ask, “Why did the agent say this?” and get a useful answer without rerunning the whole conversation from memory.
The practical direction is an evidence-first agent pattern:
source corpus -> retrieval -> cited answer -> eval check -> review gate -> next actionThis is the boundary I care about: a fluent assistant on one side, an inspectable research workflow on the other.
A useful scientific-agent surface would show:
- the answer
- the cited sources
- the retrieved chunks or source sections
- the agent’s planned next step
- the evaluation or smoke-test status
- what would change the conclusion
That surface is more valuable than a longer answer. It lets the reader inspect the reasoning.
My current position
PaperQA2 is worth watching because it points toward a better unit of scientific AI work: a reviewable research artifact.
That artifact might be a literature answer, a candidate molecule shortlist, an experiment plan, a contradiction report, or a reading map. In each case, the pattern is similar:
- Make the question explicit.
- Gather evidence from a known corpus.
- Convert evidence into claims.
- Attach citations to claims.
- Show uncertainty or conflict.
- Propose the next action.
- Leave a trace for review.
That is the style of AI for Science I am most interested in: accountable workflow over performance theater.
Watch-for
I would not treat repository popularity, benchmark language, or “AI scientist” framing as evidence of reliability. They are signals to investigate.
The real question is narrower and more useful:
Can the system answer a known scientific question, cite the right evidence, expose its uncertainty, and make the next step easier to inspect?
That is the kind of small, repeatable test I would want to run before building on top of it.
Source: Future-House/paper-qa and the PaperQA2 paper on arXiv. Source figures are attributed to Skarlinski et al. under CC BY-SA 4.0. The SciencesLoop diagrams in this post are conceptual interpretations, not source figures.
Conclusion
My takeaway is simple: I would trust a scientific RAG system less for how fluent the answer sounds, and more for whether the evidence trail can be inspected.
If an agent can answer, cite, expose uncertainty, and show the path from question to evidence to next action, it starts to become useful scientific infrastructure. If it cannot show that path, it is still mostly a fluent interface.
The practical test I would start with is small: known-answer scientific questions, near-miss papers, citation checks, caveat checks, and replayable retrieval traces.
Discuss this note
Email feedbackComments will use a logged-in, moderated GitHub Discussions flow once it is configured. For now, send feedback directly.