PaperQA2 给 scientific RAG 的一个提醒:答案之外,要留下证据链
一篇 SciencesLoop technical note:从 Future House 的 PaperQA2 看引用精度、证据链和可审查的科研 RAG artifact。
PaperQA2 给 scientific RAG 的一个提醒:答案之外,要留下证据链。
做材料和电池文献综述时,找到论文只是第一步。更麻烦的是判断一个结论到底由哪些证据支撑:实验条件是不是可比,有没有 negative result,引用的 section 是否真的支持这个 claim,以及这个判断会不会改变下一步实验。
这也是我读 Future-House/paper-qa 时最先抓住的点。它是 PaperQA2 背后的开源仓库,相关论文是 Language agents achieve superhuman synthesis of scientific knowledge。
我的读法是:PaperQA2 值得关注,因为它把文献问答拆成了一组可以检查的动作:search、evidence selection、reasoning over cited material、answer generation 和 evaluation。引用是最后露出来的一层,evidence path 才是我会想审查的部分。
SciencesLoop Signal Card
工作流判断
PaperQA2 证据链模式
这条 signal 的重点是从 source search 到 cited claim,再到可审查下一步的路径。 我已经读了 repo 和论文;还没有本地运行 PaperQA2。
Workflow stage Evidence -> evaluation -> reproducibility
- Signal
- Future House PaperQA2 repo + arXiv paper
- Run status
- 已读 repo 和论文;还没有本地运行
- Practical test
- Known-answer questions、near-miss papers 和 trace replay
-
Evidence qualityMed-high
-
ReproducibilityMedium
-
Workflow utilityHigh
-
Hype riskMedium
我关注它的原因:evidence trail 是一个可复用的 research artifact 模式; 论文里较强的 performance framing 仍然需要独立测试。
源材料实际说了什么
从公开 README 看,PaperQA2 被定位成一个面向科学文献的高准确率 RAG 包。README 里提到几个具体系统能力:
- 带文内 citation 的 grounded answer
- metadata-aware 的文档处理
- LLM-based reranking 和 contextual summarization
- agentic RAG,也就是系统可以迭代改进 query 和 answer
- 对本地文档库做 full-text search
- 通过 LiteLLM 支持可配置的模型和 embedding backend
论文里的图更清楚地说明了一点:PaperQA2 被表述成一个包含 search、answering、contradiction detection 和 evaluation 的 agentic toolset。论文也报告了 question answering、article summarization、contradiction detection 等任务上的 benchmark 结果。这里我把这些都当作源论文自己的 claim;这不等同于我已经独立复现过结果。
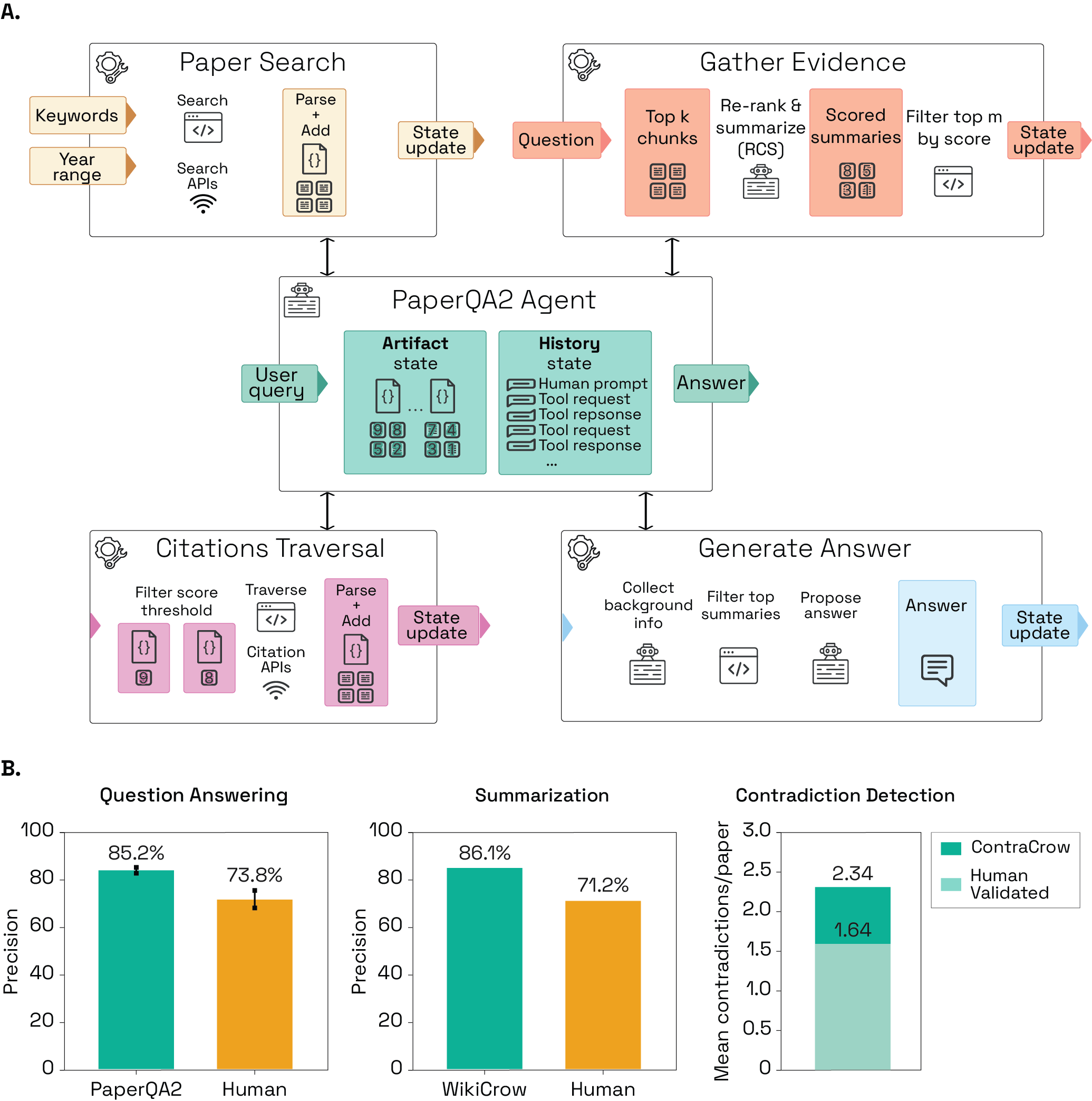
这张图对 SciencesLoop 有价值,因为它把 search tools、answer generation、citation behavior 和 evaluation 放在同一个框架里。真实科研工作也更像这样:一个问题会先展开成一系列证据操作,然后才进入判断。
有用的模式
对 scientific agent 来说,答案只是一个 artifact。另一个科学家真正需要检查的是路径。

这更接近 lab notebook 的精神,和普通 chatbot 的一次性回答不同。实验记录本不会只写“这个 electrolyte 看起来不错”。它会记录测了什么,在什么条件下测的,什么失败了,下一步合理测试是什么。Scientific RAG 也应该有类似精神:回答之后还能被检查。
我想保留下来的设计点,是把每一步都当作 work product:
- query 是 work product,因为它定义了系统实际搜索了什么。
- retrieved papers 和 source sections 是 work product,因为它们定义了证据基础。
- extracted claims 是 work product,因为它们可以回到原文核查。
- answer 是 work product,因为它总结了一个判断。
- caveat 是 work product,因为它控制过度自信。
- next step 是 work product,因为它把阅读连接到行动。
这是我想带进 SciencesLoop 的部分:让 agent 产出一个 scientist 可以 audit、correct、reuse 的东西。
一个具体场景
想象一个电池研究者问:
哪些 redox-active molecule classes 有证据显示在 nonaqueous flow batteries 里稳定性更好?
一个弱 assistant 会给出一段很自信的总结,再列几个 paper title。这可以帮助入门,但后续的 trust work 仍然全部留给研究者。
更强的 scientific workflow 应该返回更结构化的东西。

表面差别不大,但实际差别很大。一个输出要求研究者信模型;另一个输出给研究者一个可以审查的对象。
这里可以用一个比喻,但要控制边界。我会避免把它叫作 “AI scientist”,这个词隐藏了太多问题。更准确的 mental model 是:
一个像 lab notebook、search analyst 和 careful reviewer 一样工作的 literature assistant。
Notebook 记录发生了什么。Search analyst 找到并排序证据。Reviewer 问证据是否真的支持 claim。三者都不替代科学家,但可以降低 inspection 的成本。
超过“更好的搜索”
Search 检索文档。科研工作需要的是一条跨越 document、claim 和 action 的责任链。
在 AI for Science 里,RAG 系统可能位于真实决策的上游:读哪篇论文,合成哪个分子,跑哪个 simulation,相信哪个 dataset,或者哪个实验 protocol 值得花时间。这样一来,retrieval layer 就进入了科学工作流本身。
PaperQA2 是一个有用信号,因为它公开材料强调 citation-grounded answers 和 agentic query refinement。一个具体 deployment 好不好,取决于 corpus、models、settings、evaluation set 和 human review process。我的实际判断标准很窄:retrieval 和 citation behavior 必须能被测试。
论文 Figure 2 也有用,因为它把 example question/answer、performance、ablation 和 retrieval-stage analysis 放在一起。我把它看作一个好的产品表达模式:把用户看到的答案和背后的 evaluation surface 一起展示。
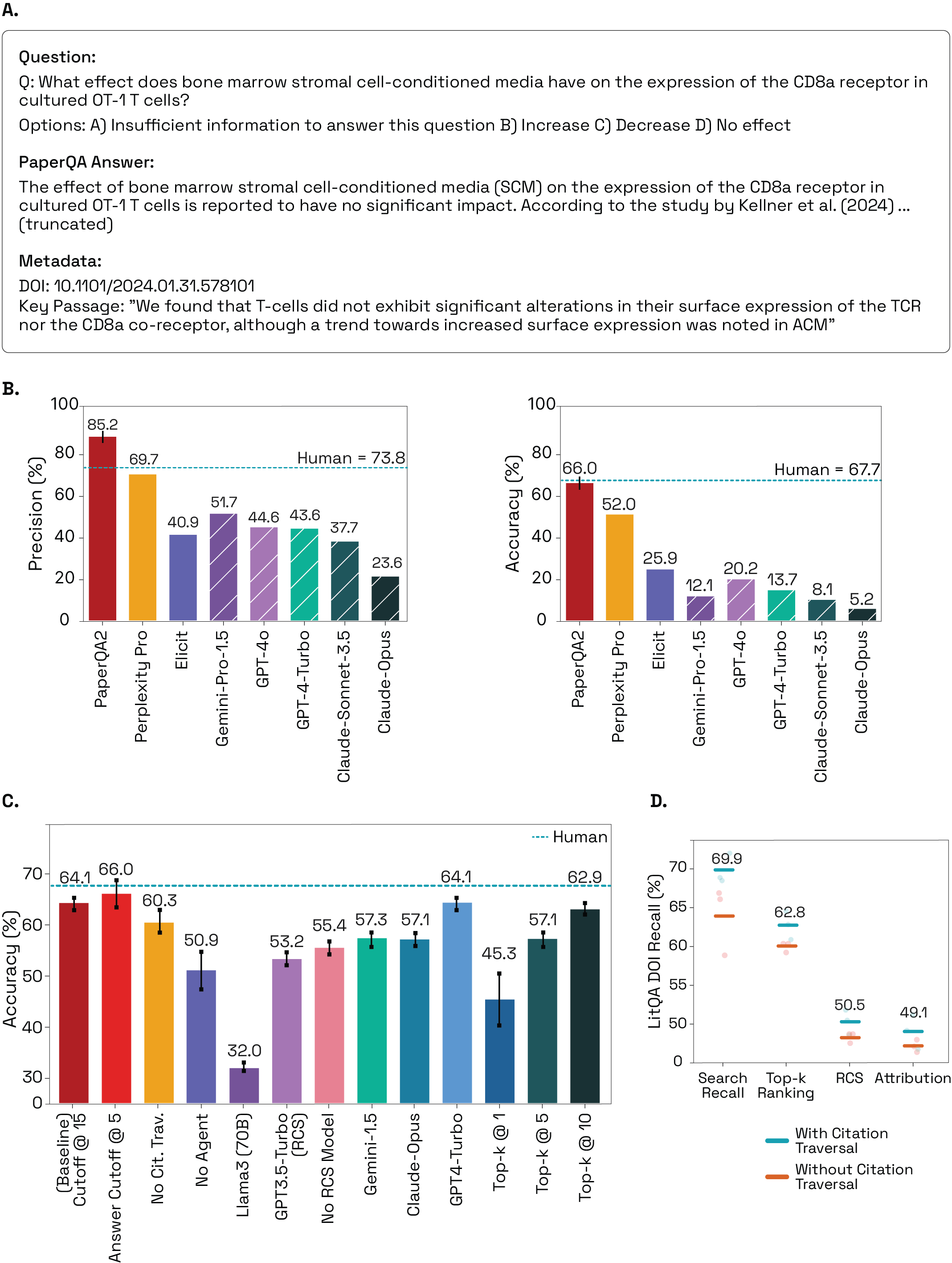
我的结论很实际:如果一个 scientific agent 不能说明它如何从 search recall 走到 selected context,再走到 attribution,那么我们很难判断这个答案是真的可靠,还是只是 fluent。
我会先怎么测试
在信任任何 scientific RAG 系统之前,我会先做一个很小的 known-answer benchmark。
例如:
- 选 20 个领域问题,每个问题都有已知 source papers。
- 加入 near-miss papers,它们术语相近,但不能真正回答问题。
- 要求系统带 citation 和 uncertainty 回答。
- 评分 citation precision、answer correctness 和 caveat visibility。
- 手工检查失败案例。

最有意思的失败通常并不夸张。更常见的是一些安静的错误:
- 系统引用了相关论文,但引用的是错误 section
- 把两个不同实验条件下的 claim 合并了
- 漏掉 negative result
- 夸大了 benchmark 或论文真正说明的东西
- 给出合理答案,但 trace 不够,无法 audit
这些才是科研工作里真正危险的失败。
所以我不希望文章或产品把 scientific agents 包装成魔法。更合理的目标是:让 reasoning path 更容易检查,让 failure cases 更容易发现,让下一步 human decision 更有依据。
SciencesLoop 的角度
对 SciencesLoop 来说,这强化了一个简单设计原则:
我希望 scientific agent 交付的不是一段漂亮回答,而是一份别人可以检查、修正、复用的 research artifact。
一个 scientific agent 界面应该展示 answer,也应该展示 evidence trail、retrieval trace、source list、evaluation result 和 next-step recommendation。科学家应该能够问:“为什么 agent 会这么说?”然后不需要从聊天记忆里重跑一遍,就能得到有用答案。
实际方向是 evidence-first agent pattern:
source corpus -> retrieval -> cited answer -> eval check -> review gate -> next action这是我关心的边界:一边是流畅 assistant,另一边是可审查的 research workflow。
一个有用的 scientific-agent surface 应该展示:
- answer
- cited sources
- retrieved chunks 或 source sections
- agent planned next step
- evaluation 或 smoke-test status
- 什么证据会改变结论
这个 surface 比更长的回答更有价值。它让读者检查 reasoning。
我的当前判断
PaperQA2 值得关注,因为它指向了一个更好的 scientific AI work unit:reviewable research artifact。
这个 artifact 可以是 literature answer、candidate molecule shortlist、experiment plan、contradiction report,或者 reading map。模式类似:
- 明确问题。
- 从已知 corpus 收集证据。
- 把证据转成 claims。
- 给 claims 附上 citations。
- 显示 uncertainty 或 conflict。
- 提出下一步 action。
- 留下可审查 trace。
这是我更感兴趣的 AI for Science:把注意力放在 accountable workflow 上,少一点 performance theater。
需要警惕什么
我不会把 repo popularity、benchmark language 或 “AI scientist” 叙事本身当作可靠性证据。它们只是值得调查的信号。
我会追的窄问题是:
系统能否回答一个已知科学问题,引用正确证据,暴露不确定性,并让下一步更容易检查?
这是我在真正构建之前想先跑的小型、可重复测试。
来源:Future-House/paper-qa 和 PaperQA2 的 arXiv 论文。源图来自 Skarlinski et al.,许可为 CC BY-SA 4.0。本文中的 SciencesLoop 图是概念解释,和论文源图分开标注。
结论
我的 takeaway 很简单:我不会只因为答案写得流畅就信任一个 scientific RAG 系统。我会先看 evidence trail 能不能被检查。
如果一个 agent 能回答、引用、暴露不确定性,并展示从 question 到 evidence 再到 next action 的路径,它才开始接近有用的科研基础设施。如果不能展示这条路径,它大多还只是一个 fluent interface。
我会从一个很小的测试开始:known-answer questions、near-miss papers、citation check、caveat check,以及 retrieval trace 能不能 replay。
讨论这篇笔记
邮件反馈评论会使用需要登录、可审核的 GitHub Discussions 流程;配置完成前,先通过邮件或 LinkedIn 反馈。